
[How to Build Tech #08] How To Actually Build End to End LLMs( with Implementation Code File) and How it Actually Works
Deep dive in the implementation...

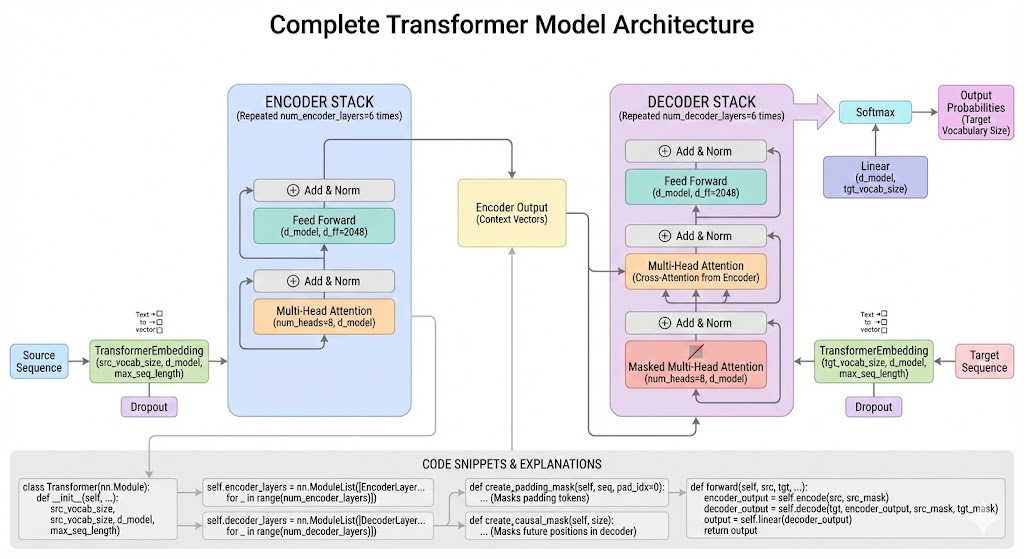
[Very Important LLM System Design #22] Encoder and Decoder: How They Actually Work
[Very Important LLM System Design #18] Quantization in LLMs: How It Actually Works
[Very Important LLM System Design #19] Transformers: How It Actually Works
[Very Important LLM System Design #16] LLM Inference : How It Actually Works
[Very Important LLM System Design #17] Attention Mechanism in LLMs: How It Actually Works
[Most Important LLM System Design #8] How RAGs Actually Work - Part 8
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
Next Post Coming Soon!
Read More : ML System Design Case Studies
[System Design Case Study #27] 3 Billion Daily Users : How Youtube Actually Scales
[System Design Tech Case Study Pulse #17] How Discord’s Real-Time Chat Scales to 200+ Million Users
LLM System Design Case Studies
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
121 implemented projects that you can use for your portfolio listed below —
LLM, Machine Learning, Deep Learning, Data Science Projects Collection
Implemented Deep Learning Projects
Implement Recurrent Neural Network using Keras to forecast Google Stock Closing Prices
Implement RNN from scratch and Build Movie Review Sentiment Analysis System
Build Complete Data Processing Pipeline (End to End project)
Build a platform that uses Machine learning to Detect Fraudulent Transactions
Implement Convolutional Neural Networks from Scratch with a Project
Build EmotionLens - Emotion Classification Using Word2Vec Embeddings
Build AutoTagger - Fast Keyword Tagging of News Articles using GloVe Embeddings
Building Movie Recommender Systems using the MovieLens Dataset
Implement Generative Adversarial Networks with MNIST Dataset: Simple GAN and DCGAN
Implemented LLM Projects
Implement and Understand LLM API and Build Chatbot with a Project
Implement Tokenization, Embeddings, Building a Simple Language Model
Sentiment Analysis on Custom Transformer Vs PreTrained Transformer
Understand and Implement Sampling from an LLM (Project Based)
Understand and Implement Fine Tuning(Project Based) - Part 2
Understand and Implement Fine Tuning(Project Based) - Part 1
Implement Different Transformer Architectures & Seq2Seq Model(Project Based)
Understand and Implement Attention and Transformer Architecture(Project Based)
Implemented Machine Learning Projects
Implement Tree Based Model & Hyperparameter tuning using Housing Dataset
Complete Time Series Analysis & Forecasting using Air Passengers Dataset
Complete Implementation of Support Vector Machines using Breast Cancer Dataset
Complete End to End Machine Learning Project for Student Performance
Complete Implementation of Spectral Clustering using Credit Card Dataset
Implement Polynomial, Regression Ridge, Lasso, Baseline Model, Cross Validation
Implement Multidimensional Scaling using Wine Quality Dataset
Implement Linear Regression to predict house prices using California Housing Dataset
Implement Linear Neural Networks, Generalization, Regularization and Weight Decay
Implement Softmax Regression & Classification with Linear Neural Networks
Complete Implementation of K-Nearest Neighbors (KNN) using Breast Cancer Dataset
Implement Gradient Boosting with the UCI Heart Disease Dataset
Implement Feature Engineering, Feature Imputation, Feature Transformation & Selection
Complete Implementation of Density Clustering using Wholesale Customers Dataset
Implement Decision Tree & Random Forests Classifiers using Drug prescriptions Dataset
Implement Convolutional Neural Networks from scratch using CIFAR-10 Dataset
Classification of Bank Loan Approvals Using Naive Bayes, Probability Distribution, MLE
Implement Ensemble Learning using Bootstrapping (Bagging Method) with a Project
Implement Learning Curve Analysis Across Multiple ML Algorithms with a Project
Implement Bias-Variance Tradeoff Analysis with Ensemble Methods
Implemented Data Analysis & Visualization Projects
Customer Segmentation & Product Analysis Using KDE and Statistical Tests
Complete Data Visualization and Analysis Using Penguins Dataset
Implemented Real-World ML Applications
Implemented Data Cleaning & Preprocessing Projects
Implemented Database & ETL Projects
This breakdown of the transformer architecture is super useful, especially seeing the encoder and decoder stacks mapped out so clearly. What really caught my attention is how you structured the pre-training implementation code alongside the theory. Most resources either go too abstract or dump code without context, but connecting the actual weight updates to the conceptual flow makes it way easier to debug when things go wrong. Have you noticed any particular bottlenecks in the training loop that beginners tend to miss?