
[How to Build Tech #03] How To Actually Build End to End Data Pipelines ( with Implementation Code) and How it Actually Works
Deep dive in the implementation...

Read : [How to Build Tech #01] The Heart of Web: Build a Load Balancer ( with Implementation Code) and How it Actually Works
[How to Build Tech #02] How To Actually Build RAG ( with Implementation Code) and How it Actually Works
Table of Contents
Introduction to Data Pipelines
Key Concepts and Components
Data Pipeline Architecture
Build Data Pipeline Real-World Example 1: E-commerce Recommendation System
Build Data Pipeline Real-World Example 2: IoT Sensor Data Processing
Build Data Pipeline Real-World Example 3: Social Media Sentiment Analysis
Best Practices and Conclusion
1. Introduction to Data Pipelines
In the modern data ecosystem, raw data is rarely useful in its original state. It is often messy, unstructured, and scattered across various silos (databases, log files, external APIs).
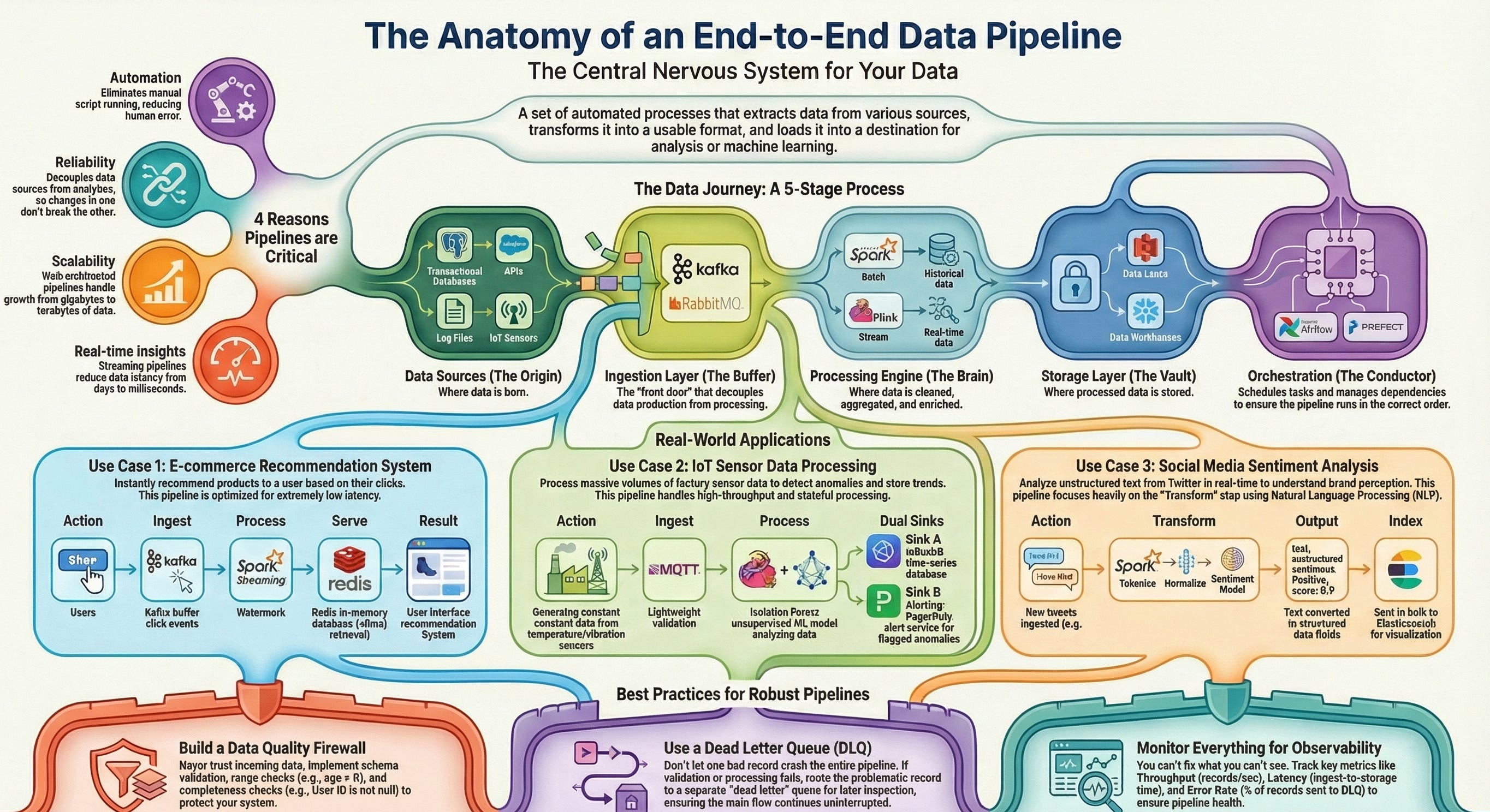
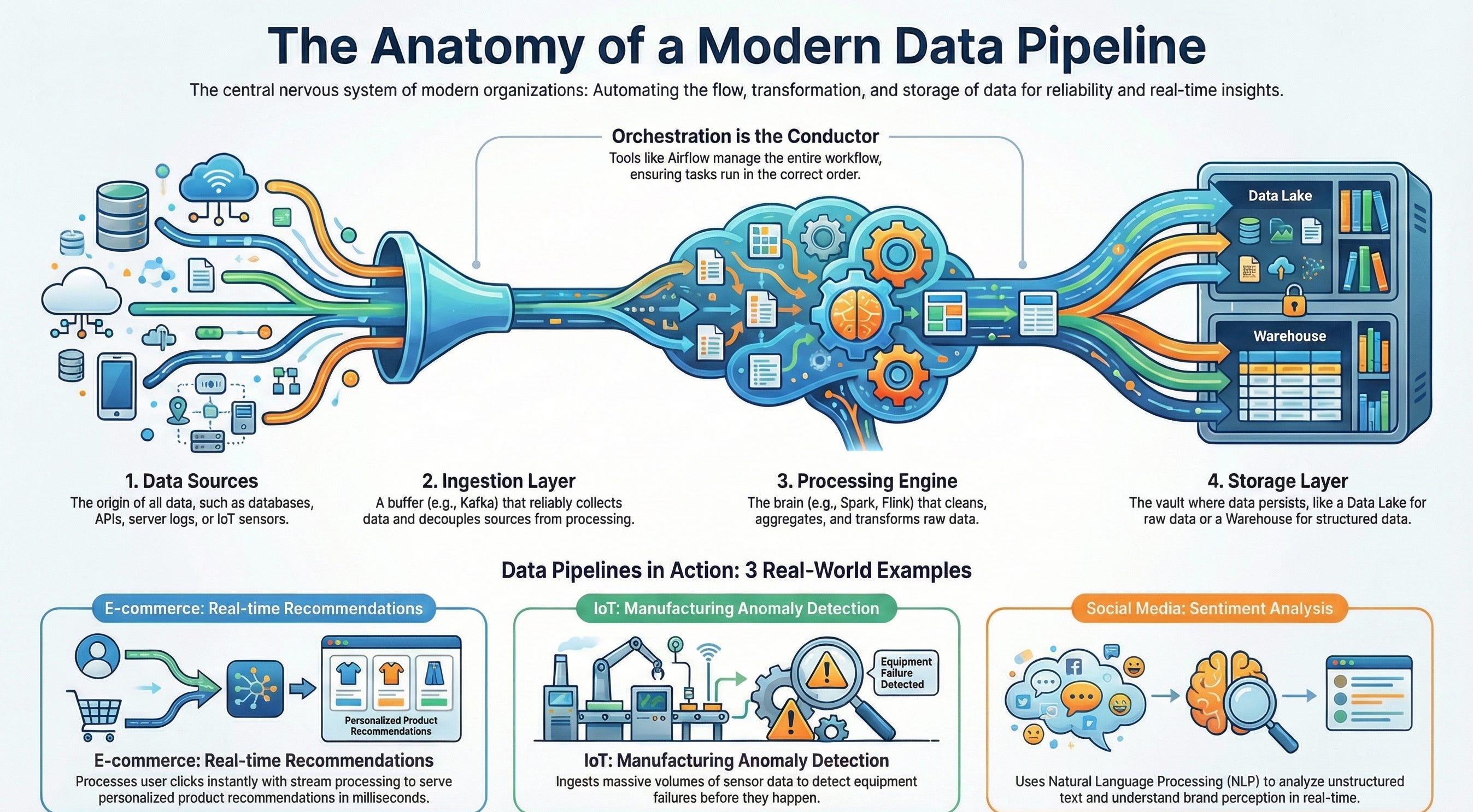
An End-to-End Data Pipeline acts as the central nervous system of an organization. It is a set of automated processes that extracts data from various sources, transforms it into a usable format, and loads it into a destination for analysis or machine learning.
Why Data Pipelines Matter
Automation: They eliminate the need for manual script running, reducing human error and freeing up engineering time.
Reliability: By decoupling data sources from consumers, pipelines ensure that if a source API changes, only the ingestion layer needs an update, not the entire analytics suite.
Scalability: A well-architected pipeline can handle the difference between 100 gigabytes and 100 terabytes of data by leveraging distributed computing (like Spark or Flink).
Real-time Insights: Modern business requires decisions in milliseconds, not days. Streaming pipelines reduce data latency to near-zero.
2. Key Concepts and Components
To build a robust system, one must understand the anatomy of a pipeline. Each component plays a specific role in the lifecycle of a data packet.
Essential Components Breakdown
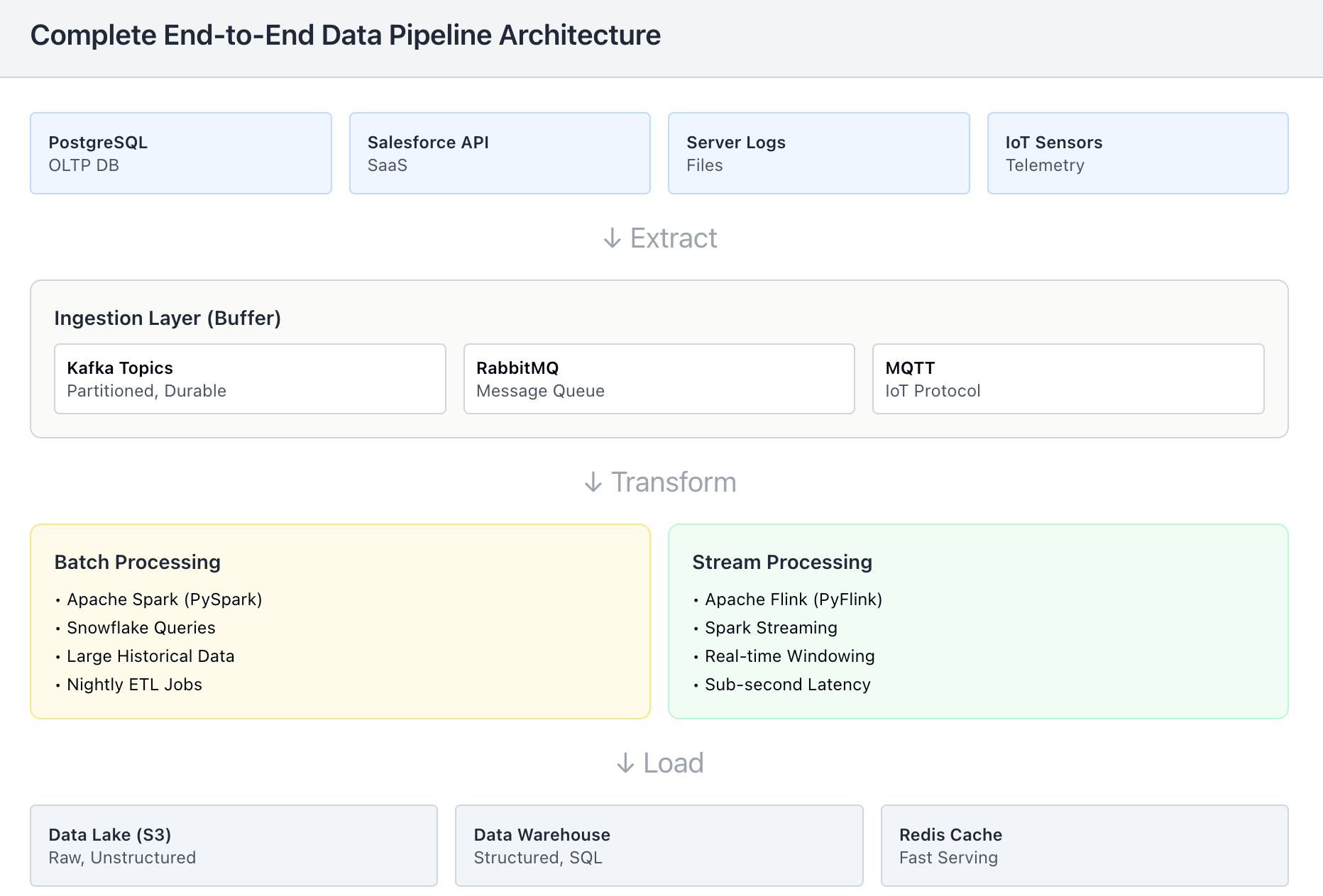
Data Sources (The Origin): This is where data is born. It could be a transactional database (PostgreSQL), a SaaS API (Salesforce, Stripe), server log files, or IoT sensors sending telemetry.
Ingestion Layer (The Buffer): The “front door” of the pipeline. It decouples the speed of data production from data processing. Tools like Apache Kafka or RabbitMQ act as buffers, holding data temporarily if the processing layer gets overwhelmed.