
[How to Build Tech #02] How To Actually Build RAG ( wit Implementation Code) and How it Actually Works
Deep dive in the implementation...

Want to create an AI that can answer questions using your own documents? The problem with large language models (LLMs) like GPT-4 is that their knowledge is frozen in time and they have no access to your private files, company wiki, or recent PDFs. How do you make an LLM an expert on your data?
The answer is Retrieval-Augmented Generation (RAG).
In this comprehensive hands on post I’ll build a complete RAG system from scratch.
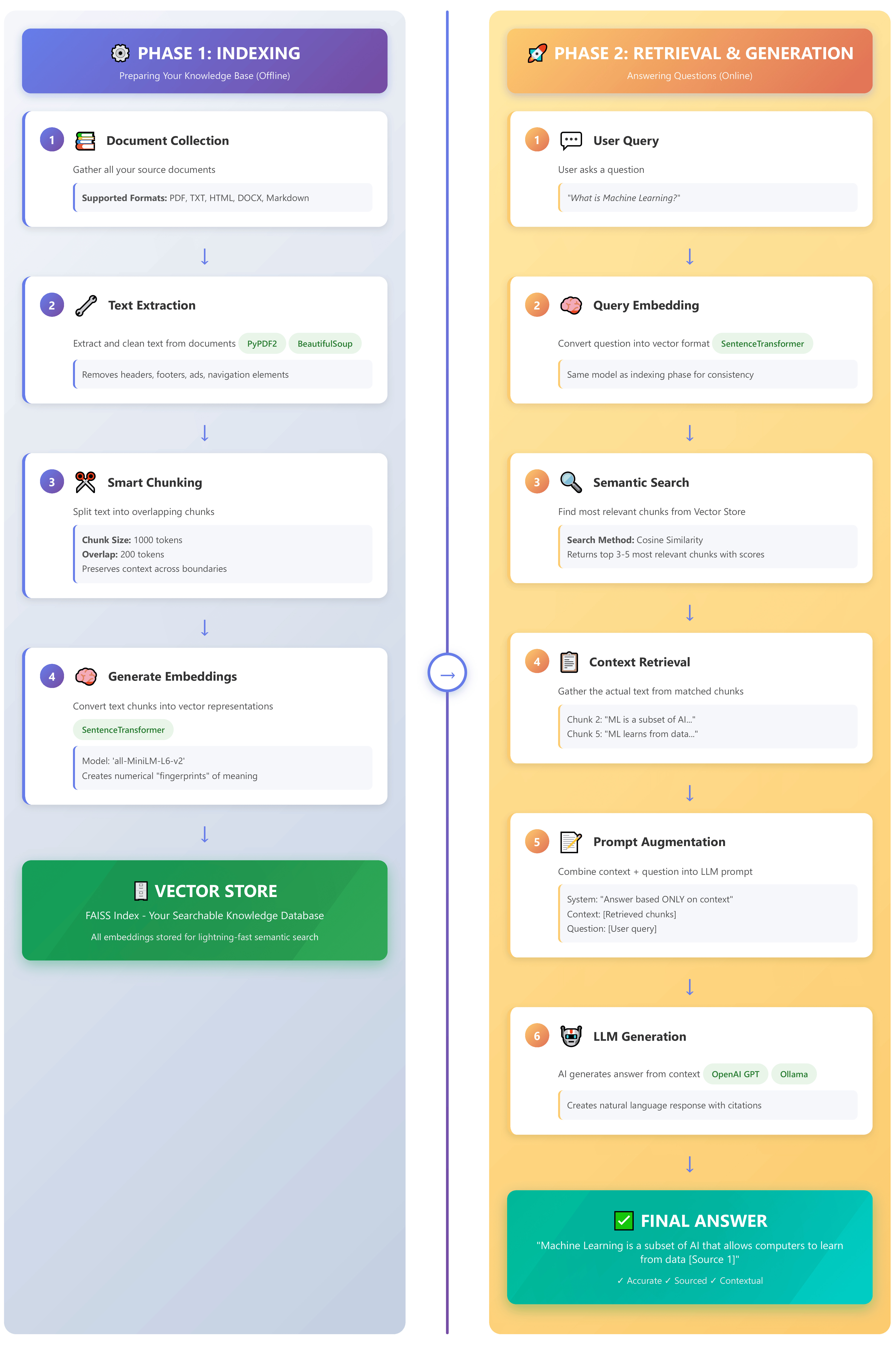
This system will ingest your documents (PDFs, websites, text files), index them in a high-speed vector database, and use an LLM to answer questions, providing accurate, sourced answers directly from your content.
What You’ll Build
By the end of this guide, you will have a complete, functioning RAG system that:
Ingests & Processes multiple document types (PDF, TXT, HTML, and live websites).
Intelligently Chunks text to preserve semantic meaning.
Embeds content into vector representations for efficient search.
Retrieves relevant context using FAISS, a lightning-fast vector store.
Generates accurate, cited answers using OpenAI (or a local Ollama model).
Includes a user-friendly web interface built with Streamlit.