
[How to Build Tech #01] The Heart of Web: Build a Load Balancer ( with Implementation Code) and How it Actually Works
Deep dive in the implementation...

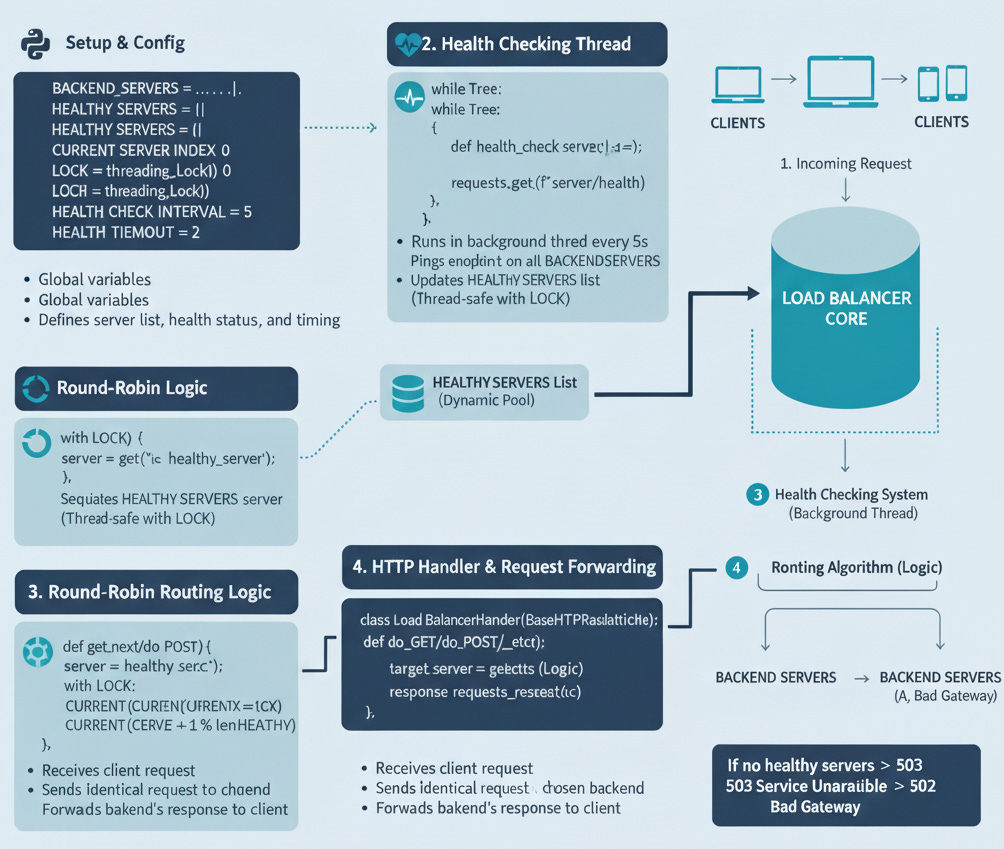
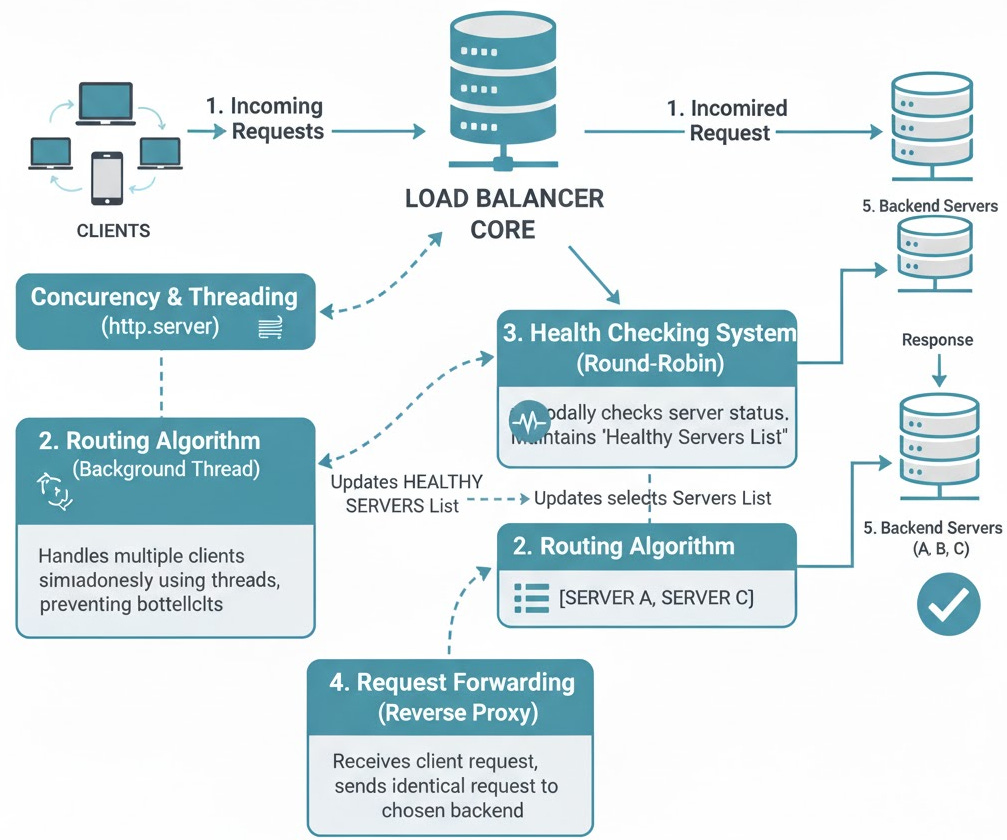
In modern web architecture, scalability and reliability aren’t optional—they’re essential. A load balancer is a critical component that makes this possible. It acts as the “traffic cop” for your network, intelligently distributing incoming requests across a group of backend servers.
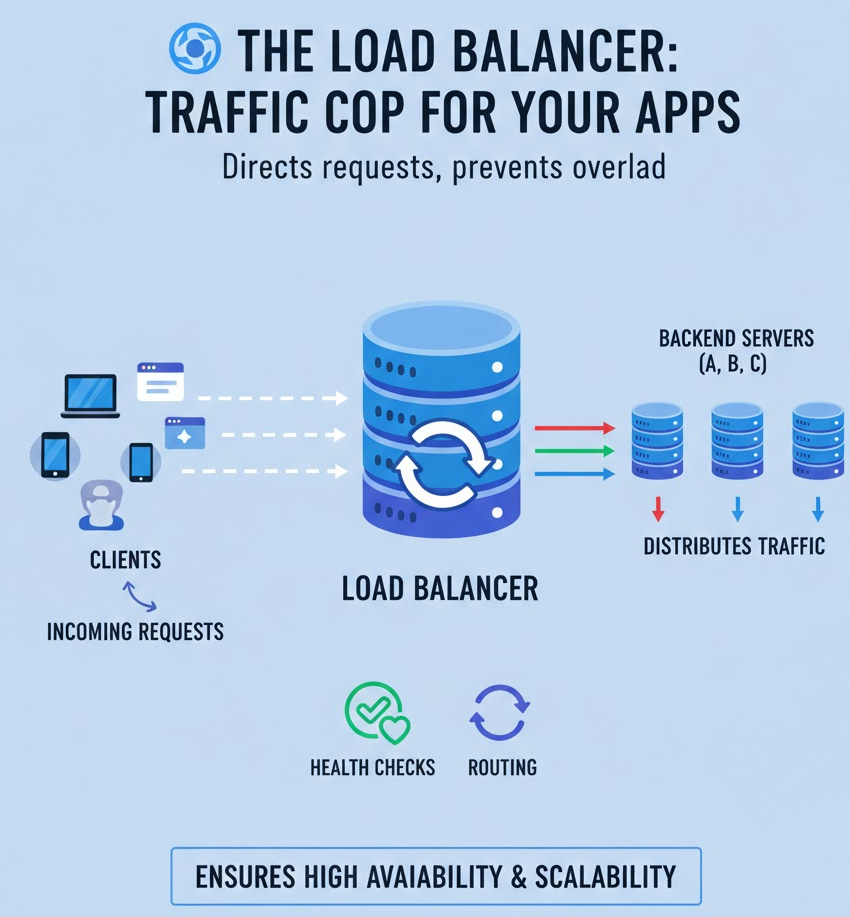
This prevents any single server from becoming a bottleneck, ensuring your application remains fast, responsive, and highly available, even under heavy traffic.
Real-World Analogy
Imagine a popular bank with only one teller. As more customers arrive, the line grows, wait times skyrocket, and the teller becomes overwhelmed.
Now, imagine the bank opens ten teller windows. A load balancer is the queue management system at the entrance. It looks at all ten tellers and directs the next customer to the teller who is available, ensuring the workload is spread evenly. If one teller goes on break (or their computer crashes), the system simply stops sending customers their way until they’re back online.
What You’ll Build
In this guide, I will build a simple, production-ready (in-concept) HTTP/S load balancer in Python from scratch.
You will learn how to implement the core components:
Backend Servers: Simple HTTP servers that do the “real” work.
Health Checking: A system to automatically detect and remove failed servers from the pool.
Routing Algorithm: A Round-Robin strategy to distribute requests fairly.
Request Forwarding: The core proxy logic to pass client requests to a healthy server.
Concurrency: Using a threaded server to handle multiple client requests at once.
Technology Stack Interconnections
I’ll use standard Python libraries to illustrate the core concepts, showing how they connect:
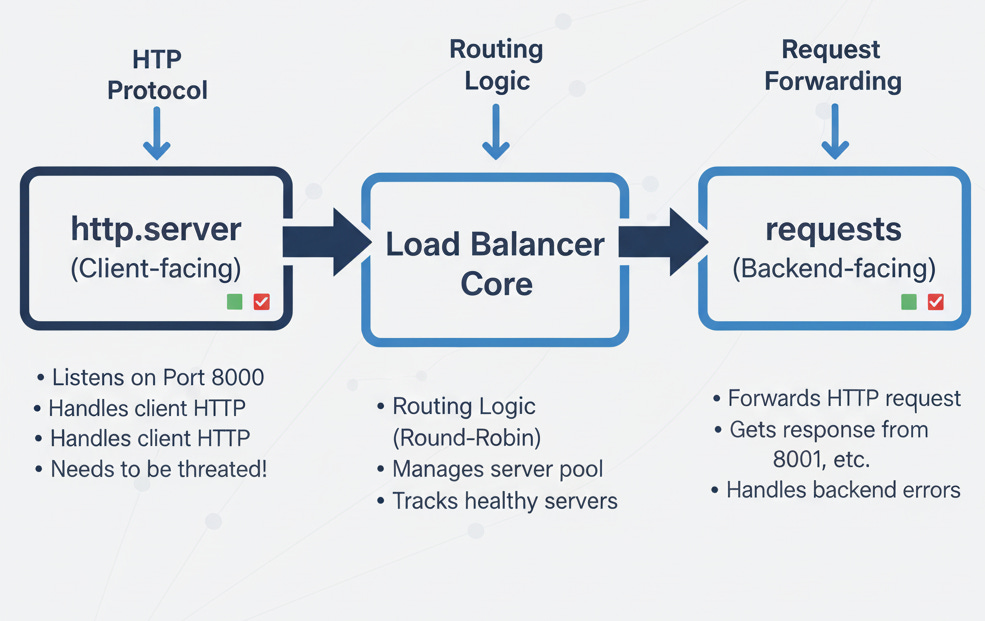
Python HTTP Ecosystem:
http.server (Client-facing) ←→ Load Balancer Core ←→ requests (Backend-facing)
↑ ↑ ↑
Listens on Port 8000 Routing Logic (Round-Robin) Forwards HTTP request
Handles client HTTP Manages server pool Gets response from 8001, etc.
Needs to be threaded! Tracks healthy servers Handles backend errors
Part 1: The Foundation (Backend Servers)
Theory: Before we can balance any load, we need a “load” to balance. These are your backend servers (also called “upstream” servers). In a real application, these servers would run your main business logic (e.g., a Node.js API, a Python Django app, etc.). For our guide, we’ll create simple Python web servers that identify themselves.
Connection: The load balancer must know the address (IP and port) of each backend server. It will treat them as interchangeable units. A crucial part of this is a /health endpoint, which the load balancer will ping to see if the server is alive.
💻 Code: backend_server.py
Create this file. We’ll run it multiple times on different ports (8001, 8002, etc.).
Python
# backend_server.py
import sys
from http.server import BaseHTTPRequestHandler, HTTPServer
import json
import os
# Get the port from the command-line arguments, default to 8001
PORT = int(sys.argv[1]) if len(sys.argv) > 1 else 8001
SERVER_ID = f”Server_on_Port_{PORT}”
class SimpleHandler(BaseHTTPRequestHandler):
def do_GET(self):
“”“Handle GET requests.”“”
if self.path == ‘/health’:
self.send_response(200)
self.send_header(’Content-type’, ‘application/json’)
self.end_headers()
self.wfile.write(json.dumps({”status”: “ok”, “server_id”: SERVER_ID}).encode(’utf-8’))
elif self.path == ‘/’:
self.send_response(200)
self.send_header(’Content-type’, ‘application/json’)
self.end_headers()
response_data = {
“message”: f”Hello from {SERVER_ID}!”,
“path”: self.path,
“headers”: dict(self.headers)
}
self.wfile.write(json.dumps(response_data).encode(’utf-8’))
else:
self.send_error(404, “Not Found”)
def do_POST(self):
“”“Handle POST requests.”“”
content_length = int(self.headers[’Content-Length’])
post_data = self.rfile.read(content_length)
self.send_response(200)
self.send_header(’Content-type’, ‘application/json’)
self.end_headers()
response_data = {
“message”: f”POST request received by {SERVER_ID}”,
“your_data”: post_data.decode(’utf-8’),
“path”: self.path,
“headers”: dict(self.headers)
}
self.wfile.write(json.dumps(response_data).encode(’utf-8’))
def run(server_class=HTTPServer, handler_class=SimpleHandler, port=PORT):
server_address = (’‘, port)
httpd = server_class(server_address, handler_class)
print(f”Starting backend server {SERVER_ID} on http://localhost:{port}...”)
httpd.serve_forever()
if __name__ == “__main__”:
run()
Part 2: The Load Balancer Implementation
Now for the main event. We’ll create a single load_balancer.py file. It will handle all the logic described in your outline.
1. The Core Class & Concurrency
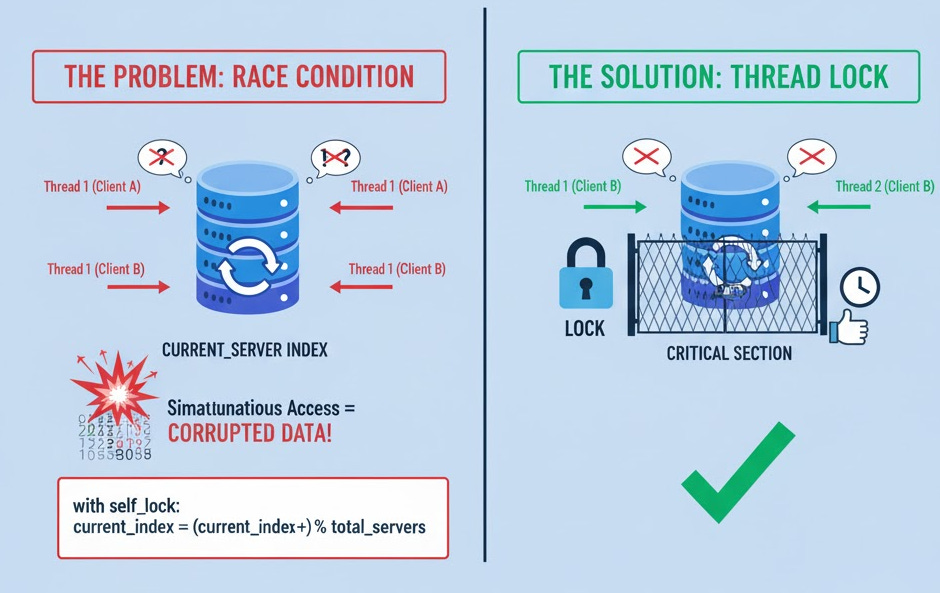
Theory: Our load balancer needs to handle many simultaneous client connections. Python’s default HTTPServer is single-threaded—it can only handle one request at a time. If we used it, a single slow request would block all other clients.
Solution: We use ThreadingHTTPServer. It spawns a new thread for each incoming connection, allowing us to handle many requests concurrently.
Thread Safety: This concurrency introduces a problem: what if two threads try to pick a server at the exact same time? They might both get the same server or corrupt the “current server” index. This is a race condition.
Solution: We use a threading.Lock. This lock ensures that only one thread can enter the “critical section” (the code that picks the next server) at a time.
2. Health Checking System
Theory: We can’t just assume our servers are online. We need an active health check system. This system will run in a separate, background thread and periodically poll the /health endpoint of each backend server.
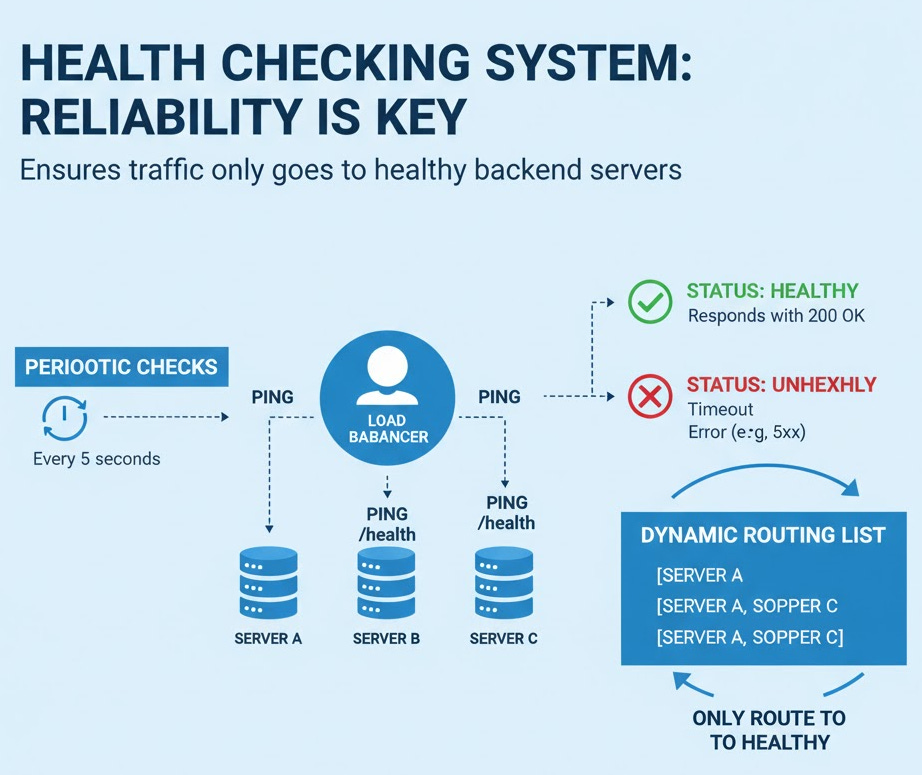
It maintains a list of “healthy” servers. The main routing logic will only ever choose from this list.
3. Round-Robin Algorithm
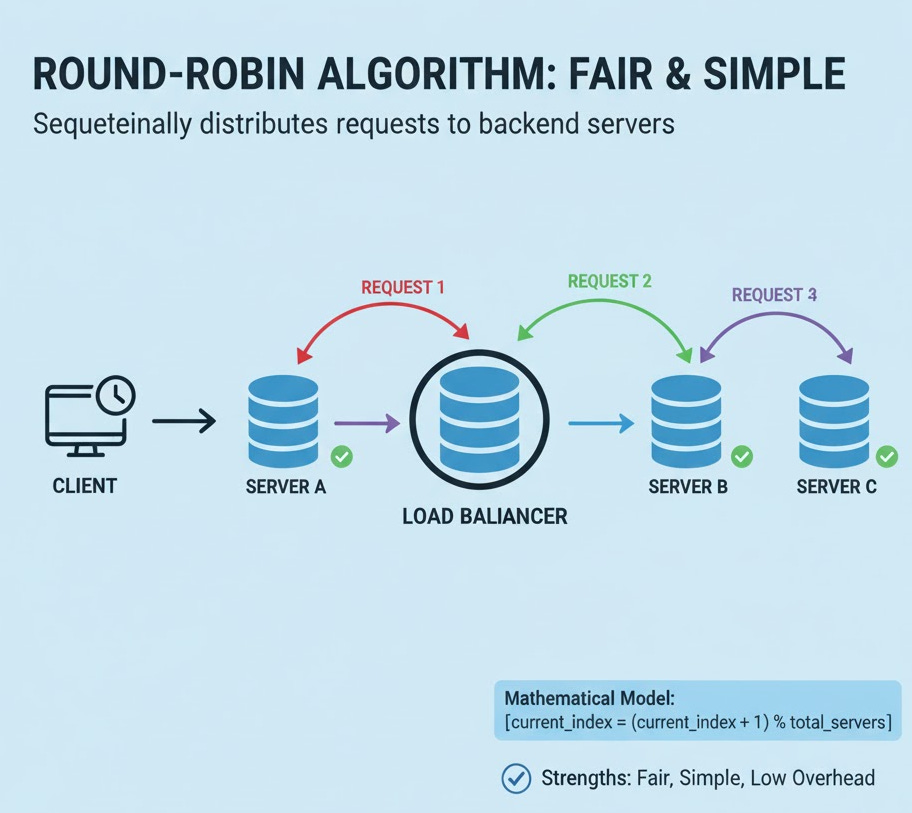
Theory: This is our distribution strategy. It’s the simplest and most common. We keep a list of healthy servers and an index.
Request 1 goes to Server A (index 0).
Request 2 goes to Server B (index 1).
Request 3 goes to Server C (index 2).
Request 4 goes back to Server A (index 0).
Mathematical Model: current_index = (current_index + 1) % total_healthy_servers
This modulo operator ensures the index wraps around to 0 when it reaches the end of the list.
4. Request Forwarding (Reverse Proxy)
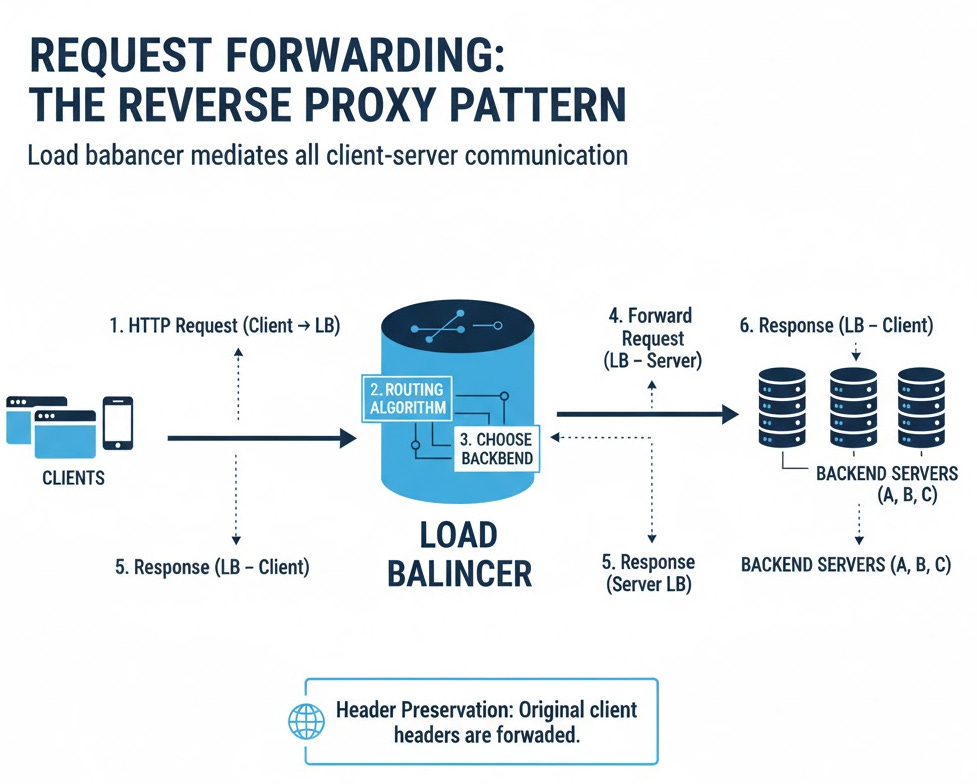
Theory: The load balancer acts as a reverse proxy. It terminates the client’s HTTP connection, starts a new HTTP connection to a chosen backend server, and then shuttles the data between them.
Data Flow:
Client connects to Load Balancer (Port 8000).
Load Balancer’s
do_GET(ordo_POST) method is triggered.Load Balancer calls its
get_next_healthy_server()function.It uses the
requestslibrary to make an identical request to the chosen backend (e.g., Port 8001).It reads the response (status code, headers, body) from the backend.
It copies this response and sends it back to the original client.
💻 Code: load_balancer.py
This file implements all the concepts above.
# load_balancer.py
from http.server import BaseHTTPRequestHandler, ThreadingHTTPServer
import requests
import threading
import time
import json
import os
# --- Configuration ---
# List of all backend servers (IP:Port)
BACKEND_SERVERS = [
“http://localhost:8001”,
“http://localhost:8002”,
“http://localhost:8003” # Add more as needed
]
# List of servers currently deemed healthy
# This list is dynamic and managed by the health checker
HEALTHY_SERVERS = []
# Current index for Round-Robin. Global to the handler’s scope
CURRENT_SERVER_INDEX = 0
# Lock for thread-safe operations on shared resources (HEALTHY_SERVERS, CURRENT_SERVER_INDEX)
LOCK = threading.Lock()
# Health check configuration
HEALTH_CHECK_INTERVAL = 5 # seconds
HEALTH_CHECK_TIMEOUT = 2 # seconds
# --- Health Checking Logic ---
def health_check_servers():
“”“
Runs in a separate thread to periodically check the health of backend servers.
Updates the global HEALTHY_SERVERS list.
“”“
global HEALTHY_SERVERS
while True:
print(f”[Health Check] Pinging backend servers... ({len(BACKEND_SERVERS)} total)”)
current_healthy_servers = []
for server in BACKEND_SERVERS:
try:
# Ping the ‘/health’ endpoint
response = requests.get(f”{server}/health”, timeout=HEALTH_CHECK_TIMEOUT)
# Check for a 200 OK status
if response.status_code == 200:
current_healthy_servers.append(server)
print(f”[Health Check] {server} is HEALTHY”)
else:
print(f”[Health Check] {server} is UNHEALTHY (Status: {response.status_code})”)
except requests.exceptions.RequestException as e:
# Timeout, connection error, etc.
print(f”[Health Check] {server} is UNHEALTHY (Error: {e.__class__.__name__})”)
# --- Critical Section: Update the global list ---
with LOCK:
HEALTHY_SERVERS = current_healthy_servers
# --- End Critical Section ---
print(f”[Health Check] Active servers: {HEALTHY_SERVERS}”)
time.sleep(HEALTH_CHECK_INTERVAL)
def get_next_healthy_server():
“”“
Uses Round-Robin to select the next healthy server.
This function is thread-safe thanks to the lock.
“”“
global CURRENT_SERVER_INDEX
# --- Critical Section: Read/Write shared variables ---
with LOCK:
if not HEALTHY_SERVERS:
# No healthy servers available
return None
# Get the next server in the list
server = HEALTHY_SERVERS[CURRENT_SERVER_INDEX]
# Update the index for the next request, wrapping around
CURRENT_SERVER_INDEX = (CURRENT_SERVER_INDEX + 1) % len(HEALTHY_SERVERS)
return server
# --- End Critical Section ---
# --- HTTP Handler & Request Forwarding ---
class LoadBalancerHandler(BaseHTTPRequestHandler):
def _forward_request(self, method):
“”“
Generic function to forward GET, POST, PUT, DELETE requests.
“”“
# Step 1: Get the next healthy backend server
target_server = get_next_healthy_server()
if target_server is None:
# --- Error Handling: No Servers Available ---
self.send_response(503) # 503 Service Unavailable
self.send_header(’Content-type’, ‘application/json’)
self.end_headers()
self.wfile.write(json.dumps({”error”: “No healthy backend servers available”}).encode(’utf-8’))
print(”[Load Balancer] Error: 503 Service Unavailable. No healthy servers.”)
return
print(f”[Load Balancer] Forwarding {method} request for {self.path} to {target_server}”)
# Step 2: Build the full target URL
target_url = f”{target_server}{self.path}”
# Step 3: Copy headers from the original client request
headers = dict(self.headers)
# Step 4: Read the request body (for POST, PUT)
body = None
if ‘Content-Length’ in headers:
content_length = int(headers[’Content-Length’])
body = self.rfile.read(content_length)
try:
# Step 5: Send the request to the backend server
# stream=True allows us to proxy the response chunk-by-chunk
response = requests.request(
method,
target_url,
headers=headers,
data=body,
timeout=5,
stream=True
)
# Step 6: Proxy the backend’s response back to the client
# Copy the status code
self.send_response(response.status_code)
# Copy all response headers
for key, value in response.headers.items():
# Avoid proxying connection-related headers
if key.lower() not in (’transfer-encoding’, ‘content-encoding’, ‘connection’):
self.send_header(key, value)
self.end_headers()
# Stream the response body
for chunk in response.iter_content(chunk_size=8192):
self.wfile.write(chunk)
except requests.exceptions.RequestException as e:
# --- Error Handling: Backend Server Failed Mid-Request ---
self.send_response(502) # 502 Bad Gateway
self.send_header(’Content-type’, ‘application/json’)
self.end_headers()
self.wfile.write(json.dumps({”error”: “Bad Gateway”, “details”: str(e)}).encode(’utf-8’))
print(f”[Load Balancer] Error: 502 Bad Gateway while contacting {target_server}. Error: {e}”)
# --- Implement HTTP Methods ---
def do_GET(self):
self._forward_request(’GET’)
def do_POST(self):
self._forward_request(’POST’)
def do_PUT(self):
self._forward_request(’PUT’)
def do_DELETE(self):
self._forward_request(’DELETE’)
# --- Main Execution ---
def run(server_class=ThreadingHTTPServer, handler_class=LoadBalancerHandler, port=8000):
# Start the health check thread
# daemon=True means the thread will exit when the main program exits
health_thread = threading.Thread(target=health_check_servers, daemon=True)
health_thread.start()
# Wait a moment for the initial health check to populate
print(”Waiting for initial health check...”)
time.sleep(HEALTH_CHECK_INTERVAL) # Give it time for the first run
print(f”Initial healthy servers: {HEALTHY_SERVERS}”)
if not HEALTHY_SERVERS:
print(”WARNING: No healthy servers found on startup. Will keep trying.”)
# Start the main, client-facing load balancer server
server_address = (’‘, port)
httpd = server_class(server_address, handler_class)
print(f”Starting load balancer on http://localhost:{port}...”)
try:
httpd.serve_forever()
except KeyboardInterrupt:
pass
httpd.server_close()
print(”Stopping load balancer...”)
if __name__ == “__main__”:
run()
Part 3: Running The System
Now, let’s see it all in action.
Save the files: Save
backend_server.pyandload_balancer.py.Open 3 Terminal/PowerShell windows for your backend servers.
python backend_server.py 8001python backend_server.py 8002python backend_server.py 8003
Open a 4th Terminal for the load balancer.
python load_balancer.py
Test the Load Balancer: Open a 5th terminal and use
curl(or your browser).
Test 1: Round-Robin
Run this command several times:
Bash
curl http://localhost:8000/
You will see the response change, cycling through your servers:
JSON
{”message”: “Hello from Server_on_Port_8001!”}
{”message”: “Hello from Server_on_Port_8002!”}
{”message”: “Hello from Server_on_Port_8003!”}
{”message”: “Hello from Server_on_Port_8001!”}
...and so on.
Test 2: Failure & Recovery
Go to one of your backend terminals (e.g., Port 8002) and press Ctrl+C to stop it.
Watch the load balancer’s terminal. Within 5 seconds, it will report:
[Health Check] http://localhost:8002 is UNHEALTHY (Error: ConnectionError)
[Health Check] Active servers: [’http://localhost:8001’, ‘http://localhost:8003’]
Now, run curl http://localhost:8000/ again. You will see it only alternates between 8001 and 8003, completely skipping the dead server.
Now, restart the server on port 8002: python backend_server.py 8002.
Within 5 seconds, the health checker will find it, and it will be added back into the rotation automatically!
Test 3: POST Requests
Bash
curl -X POST -d “mydata=123” http://localhost:8000/
Output:
JSON
{
“message”: “POST request received by Server_on_Port_8001”,
“your_data”: “mydata=123”,
...
}
It works! The load balancer correctly forwarded the method, headers, and body.
Part 4: Advanced Features Roadmap (Theory)
Our simple load balancer is great, but real-world systems like Nginx or AWS ELB have more advanced features. Here’s how they build on our concepts.
Weighted Round-Robin
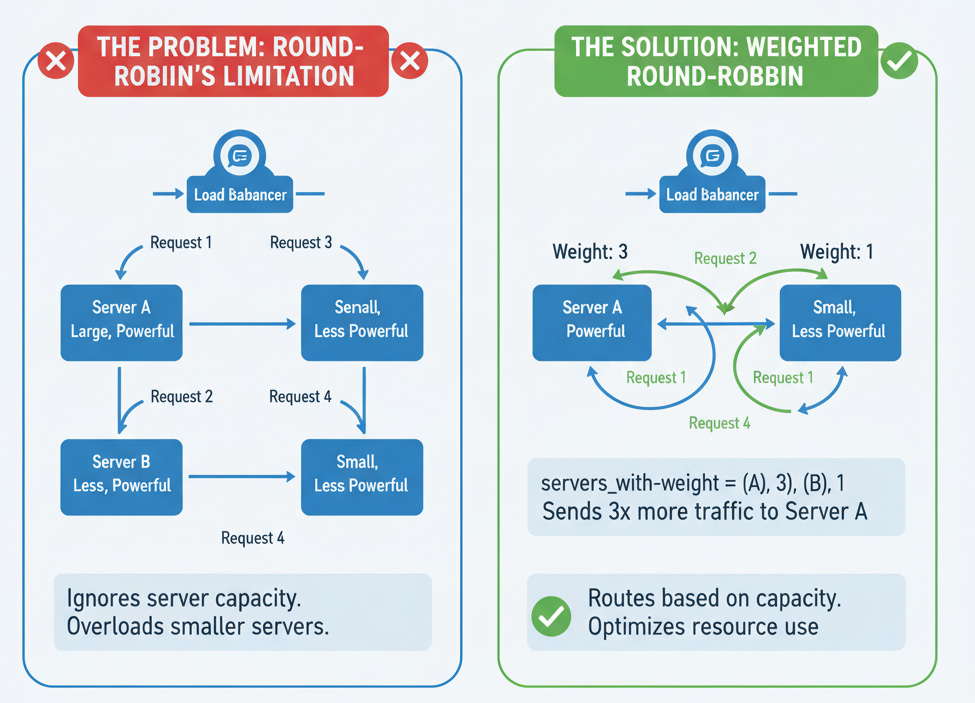
Theory: Our Round-Robin assumes all servers are equal. What if Server A is a powerful machine and Server B is a small one? We should send Server A more traffic.
Implementation Concept: You’d assign a “weight” to each server (e.g., {’server’: ‘A’, ‘weight’: 3}, {’server’: ‘B’, ‘weight’: 1}). The algorithm would send 3 requests to A for every 1 request it sends to B.
Pseudo-code:
Python
# Server list: [A, A, A, B]
# Or, a sequence generator:
servers_with_weight = [
(server1, 3),
(server2, 1),
(server3, 2)
]
# A more complex algorithm would then pick from this list
# respecting the weights, often using a “current_weight” tracker.
Least Connections Algorithm
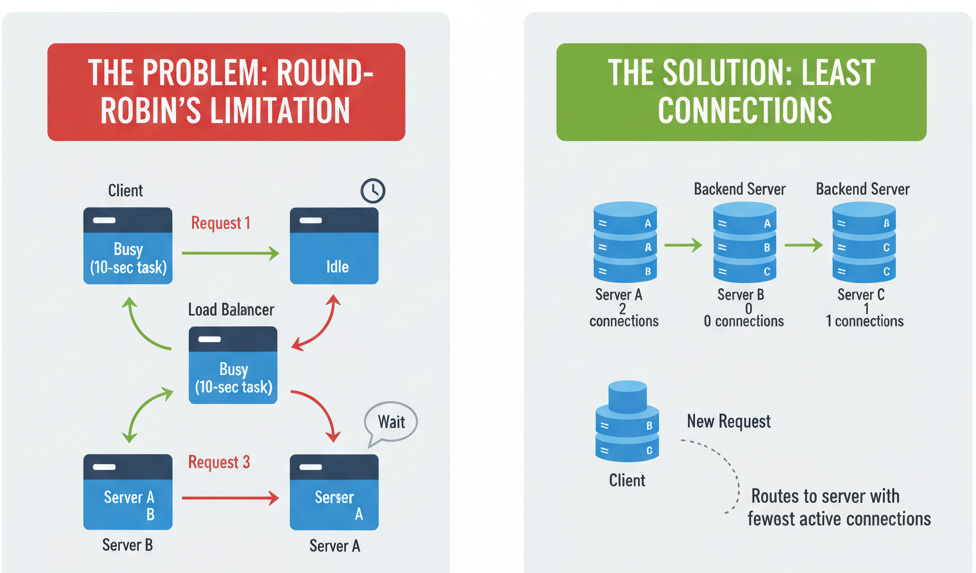
Theory: Round-Robin is “dumb”—it doesn’t care about a server’s current load. What if Server A got a very slow, complex request that will take 10 seconds, while Server B is idle? Round-Robin would still send the next request to Server B, then the next to Server A (which is still busy!).
Solution: The load balancer maintains a counter of active connections for each server. It always sends the next request to the server with the fewest active connections.
Implementation Concept:
Python
# We’d need to increment/decrement a counter for each server
# server_connections = {’A’: 5, ‘B’: 2, ‘C’: 4}
def get_least_connections_server():
with lock:
# Find the server with the minimum value in our connection dict
chosen_server = min(server_connections, key=server_connections.get)
# Increment its count before returning
server_connections[chosen_server] += 1
return chosen_server
# We would also need to decrement the count when a request finishes
Session Persistence (Sticky Sessions)
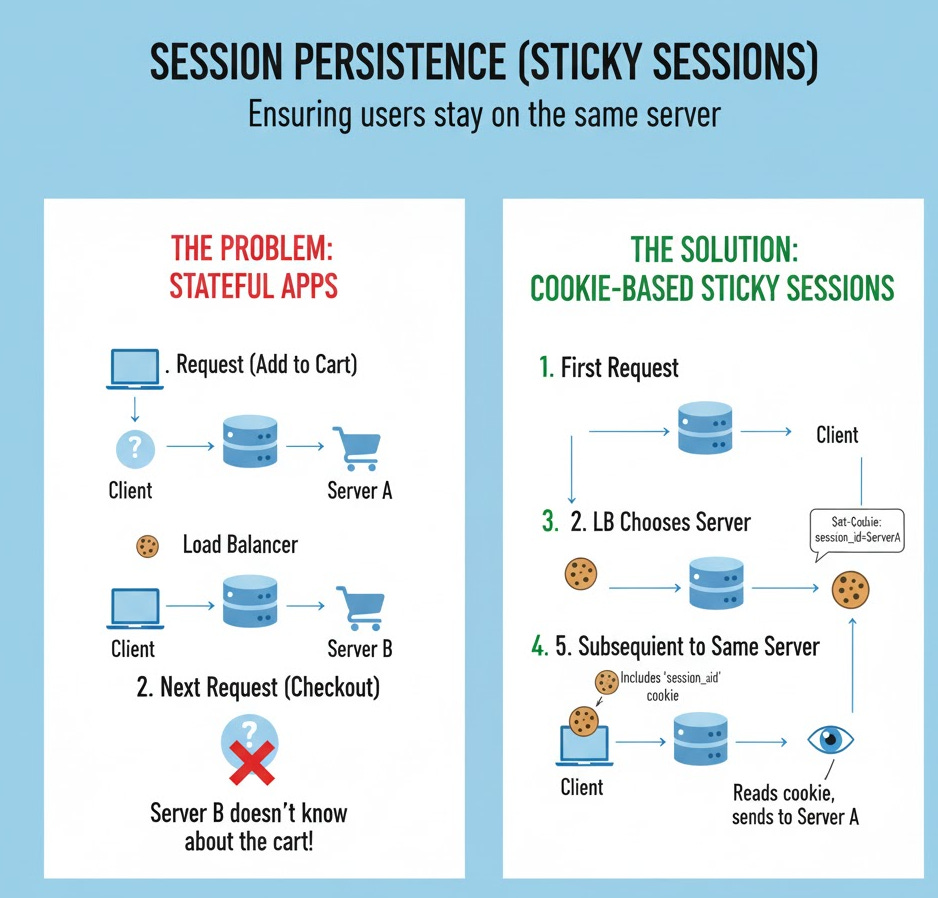
Theory: Some applications are stateful. They store user data (like a shopping cart) in that server’s memory. If Request 1 (add to cart) goes to Server A, and Request 2 (checkout) goes to Server B, Server B won’t know about the shopping cart!
Solution: “Sticky sessions.” The load balancer ensures that all requests from the same user go to the same server.
Implementation Concept (Cookie-based):
First Request: User requests a page.
Load Balancer: Picks Server A (using Round-Robin).
Load Balancer: Before sending the response back to the client, it adds a cookie:
Set-Cookie: session_id=serverA.Subsequent Requests: The client’s browser automatically includes this cookie.
Load Balancer: Reads the cookie. “Ah,
session_id=serverA. I must send this to Server A,” (as long as Server A is healthy).
SSL Termination
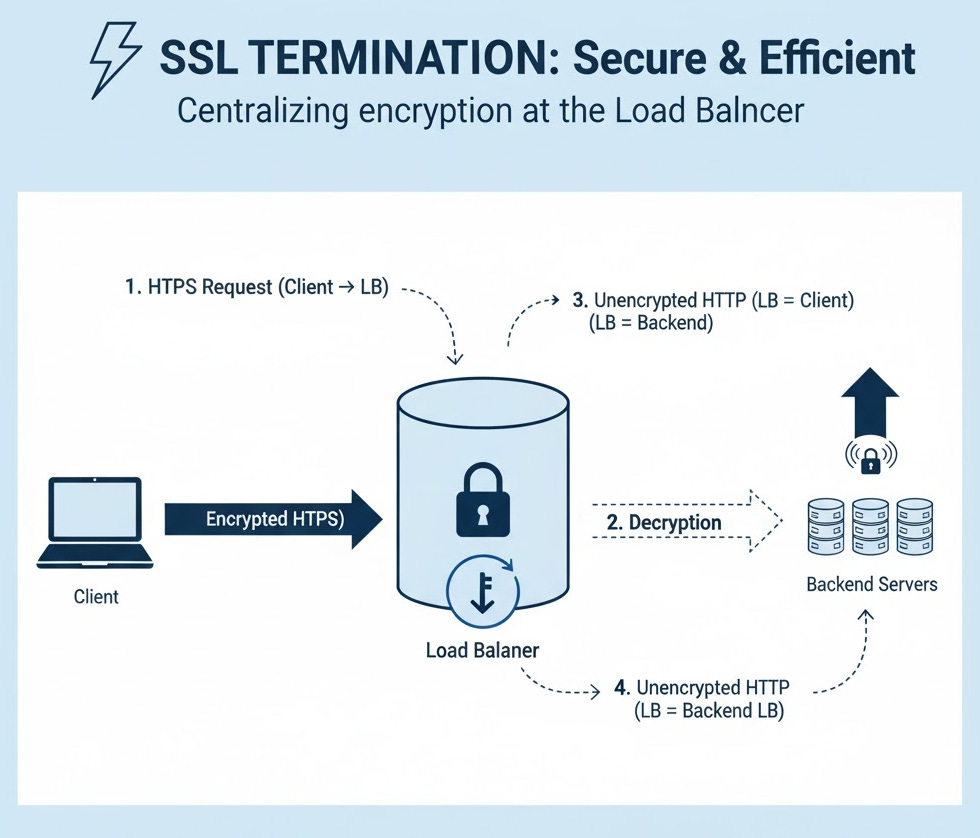
Theory: Handling HTTPS (SSL/TLS) encryption and decryption is computationally expensive. Instead of making every backend server do this work, the load balancer can do it once, in a central place.
Flow:
Client → Load Balancer: Encrypted HTTPS request.
Load Balancer: Decrypts the request.
Load Balancer → Backend Server: Plain, unencrypted HTTP request (this is faster, as it’s on a secure internal network).
Backend Server → Load Balancer: Plain HTTP response.
Load Balancer → Client: Encrypts the response and sends it as HTTPS.
Rate Limiting & Circuit Breakers
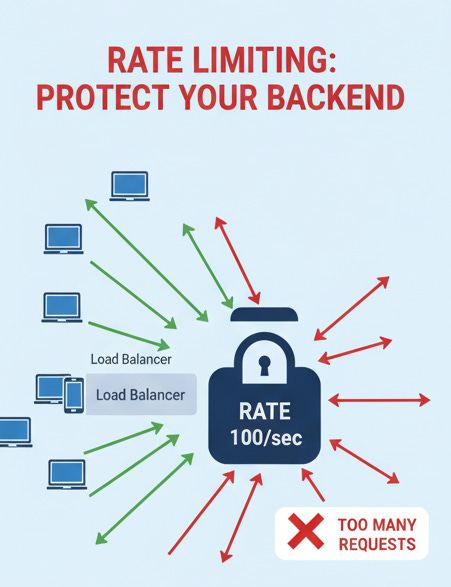
Rate Limiting: Protects your backend from abuse or “denial of service” (DoS) attacks. The load balancer can be configured to only allow X requests per second from a single IP. Any more are rejected with a
429 Too Many Requestserror.Circuit Breaker: An advanced health check. If a server starts failing a lot (e.g., 50% of requests fail), the load balancer “trips a circuit” and stops sending any traffic to it for a set time (e.g., 30 seconds) to give it time to recover, preventing cascading failures.
Conclusion
You’ve successfully built a functional, concurrent load balancer in Python! You’ve implemented the core components of a modern web architecture: service distribution (Round-Robin), resilience (health checks), and concurrency (threading).
This foundation is the basis for all load balancing, from simple projects to the massive, globally-distributed systems run by Google and Amazon.
ML System Design Case Studies
[System Design Case Study #27] 3 Billion Daily Users : How Youtube Actually Scales
[System Design Tech Case Study Pulse #17] How Discord’s Real-Time Chat Scales to 200+ Million Users
LLM System Design Case Studies
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
121 implemented projects that you can use for your portfolio listed below —
LLM, Machine Learning, Deep Learning, Data Science Projects Collection
Implemented Deep Learning Projects
Implement Recurrent Neural Network using Keras to forecast Google Stock Closing Prices
Implement RNN from scratch and Build Movie Review Sentiment Analysis System
Build Complete Data Processing Pipeline (End to End project)
Build a platform that uses Machine learning to Detect Fraudulent Transactions
Implement Convolutional Neural Networks from Scratch with a Project
Build EmotionLens - Emotion Classification Using Word2Vec Embeddings
Build AutoTagger - Fast Keyword Tagging of News Articles using GloVe Embeddings
Building Movie Recommender Systems using the MovieLens Dataset
Implement Generative Adversarial Networks with MNIST Dataset: Simple GAN and DCGAN
Implemented LLM Projects
Implement and Understand LLM API and Build Chatbot with a Project
Implement Tokenization, Embeddings, Building a Simple Language Model
Sentiment Analysis on Custom Transformer Vs PreTrained Transformer
Understand and Implement Sampling from an LLM (Project Based)
Understand and Implement Fine Tuning(Project Based) - Part 2
Understand and Implement Fine Tuning(Project Based) - Part 1
Implement Different Transformer Architectures & Seq2Seq Model(Project Based)
Understand and Implement Attention and Transformer Architecture(Project Based)
Implemented Machine Learning Projects
Implement Tree Based Model & Hyperparameter tuning using Housing Dataset
Complete Time Series Analysis & Forecasting using Air Passengers Dataset
Complete Implementation of Support Vector Machines using Breast Cancer Dataset
Complete End to End Machine Learning Project for Student Performance
Complete Implementation of Spectral Clustering using Credit Card Dataset
Implement Polynomial, Regression Ridge, Lasso, Baseline Model, Cross Validation
Implement Multidimensional Scaling using Wine Quality Dataset
Implement Linear Regression to predict house prices using California Housing Dataset
Implement Linear Neural Networks, Generalization, Regularization and Weight Decay
Implement Softmax Regression & Classification with Linear Neural Networks
Complete Implementation of K-Nearest Neighbors (KNN) using Breast Cancer Dataset
Implement Gradient Boosting with the UCI Heart Disease Dataset
Implement Feature Engineering, Feature Imputation, Feature Transformation & Selection
Complete Implementation of Density Clustering using Wholesale Customers Dataset
Implement Decision Tree & Random Forests Classifiers using Drug prescriptions Dataset
Implement Convolutional Neural Networks from scratch using CIFAR-10 Dataset
Classification of Bank Loan Approvals Using Naive Bayes, Probability Distribution, MLE
Implement Ensemble Learning using Bootstrapping (Bagging Method) with a Project
Implement Learning Curve Analysis Across Multiple ML Algorithms with a Project
Implement Bias-Variance Tradeoff Analysis with Ensemble Methods
Implemented Data Analysis & Visualization Projects
Customer Segmentation & Product Analysis Using KDE and Statistical Tests
Complete Data Visualization and Analysis Using Penguins Dataset
Implemented Real-World ML Applications
Implemented Data Cleaning & Preprocessing Projects
Implemented Database & ETL Projects